
世界初 「マルチユーザーGPUテクノロジー」による ハードウェアベースのGPU 「AMD FirePro™ S7150×2」「AMD FirePro™ S7150」を発表
【概要】
株式会社エーキューブ(本社:東京都千代田区、代表取締役:武藤和彦)は、世界初「マルチユーザーGPUテクノロジー(MxGPU)」を搭載した仮想化向けグラフィックスボード「AMD FirePro™ S7150」を発表しました。
PCI Express® 3.0をフルサポートし、OpenCL™プログラミング言語の使用に合わせて最適化されている「AMD FirePro™ S7150」は、ECCメモリと16GB GDDR5メモリ(S7150x2)、8GB GDDR5メモリ(S7150)を特長としており、大規模モデルやアセンブリーを扱う開発者は最新のAMDグラフィックス・コア・ネクスト(GCN)アーキテクチャーをベースにするAMD GPUの超並列処理能力を活用することができます。
世界初と謳っている「マルチユーザーGPUテクノロジー(MxGPU)」により、 複数の仮想化マシンからのI/O要求をハードウェアベースで行うことが可能になるため、性能を大幅に向上させることができます。また、AMD FirePro™S7150×2は最大32ユーザーまで、AMD FirePro™S7150は最大16ユーザーまで同時利用が可能となっております。
「AMD FirePro™ S7150」は2016年2月下旬頃発売予定です。
株式会社エーキューブ(本社:東京都千代田区、代表取締役:武藤和彦)は、世界初「マルチユーザーGPUテクノロジー(MxGPU)」を搭載した仮想化向けグラフィックスボード「AMD FirePro™ S7150」を発表しました。
PCI Express® 3.0をフルサポートし、OpenCL™プログラミング言語の使用に合わせて最適化されている「AMD FirePro™ S7150」は、ECCメモリと16GB GDDR5メモリ(S7150x2)、8GB GDDR5メモリ(S7150)を特長としており、大規模モデルやアセンブリーを扱う開発者は最新のAMDグラフィックス・コア・ネクスト(GCN)アーキテクチャーをベースにするAMD GPUの超並列処理能力を活用することができます。
世界初と謳っている「マルチユーザーGPUテクノロジー(MxGPU)」により、 複数の仮想化マシンからのI/O要求をハードウェアベースで行うことが可能になるため、性能を大幅に向上させることができます。また、AMD FirePro™S7150×2は最大32ユーザーまで、AMD FirePro™S7150は最大16ユーザーまで同時利用が可能となっております。
「AMD FirePro™ S7150」は2016年2月下旬頃発売予定です。
AMDがSC15にて、「Boltzmann Initiative」を発表 – AMD GPU用C++とCUDAコンパイラー
News from : Anandtech.com

サーバーカード、FirePro SシリーズのHPC能力に焦点あてたるためのショーに専念するAMDから、SC15における重要な第2番目のアナウンスが発表されました。
我々が過去2週間傍聴した事前説明会のすべての中でも、本日のAMDの発表はこれまで最も重要なことです。そして、それは SCがAMDのホームグラウンド、テキサス州オースティンで開催された時にこれが発表されたことは当然のことといえます。
何がAMDを熱狂させたのでしょうか? 要約すると、同社はHPCソフトウェア計画の大規模な見直しに着手しようとしています。統計力学の父、ルードリッヒ・ボルツマンにちなんでボルツマン・イニシアティブと呼ばれています。NVIDIAとのギャップを埋めて競争(および互換性!)環境を提供するために、AMDは彼らのHPCソフトウェアエコシステムの再開発努力にもっと取り組むことになるでしょう。このことを念頭に置いて、先に進んでみましょう。

ヘッドレスLinuxとHSAベースGPUの環境
おそらく、ボルツマン・イニシアティブの土台は、AMDの他の計画をサポートするために見直しと改善されたAMDのドライバーと共にあります。同社は、特にLinuxのヘッドレス操作のために専用の64-bit Linuxドライバーをビルドすることになるでしょう。AMDは実際、Linuxのヘッドレス操作(そのヘッドレスOpenCLに先立った実行環境はすこしハッキング気味でしたが)と完成した新しいドライバに昨年からフォーカスしてきました。

しかしそのことよりも重要なのは、ヘッドレスLinuxドライバは、HSA拡張環境を実装するだろうことです。それは、AMDのFireProディスクリートGPUにヘテロジニアス・システム・アーキテクチャ(HSA)の多くの利点をもたらすでしょう。AMDがHSA+と呼んでいるこの環境は、特にディスクリートGPUでHSAをサポートするための拡張機能を追加することで、正式なHSA規格を作り直します。拡張機能自体は標準規格にはならない予定ですが、HSAファウンデーションは、APU風の真のインテグレートデバイスに焦点をあてているので、それらの拡張機能はすぐに主流のHSAとして上流で受け入れられそうにはありません。このため、AMDは将来この拡張機能をオープンソースとしてリリースするでしょう。
ディスクリートGPU(dGPU)にHSAを拡張する目的は、以前の約束を満たす以外にも、dGPUに実用的なHSA実行モデルの利点を出来る限り多くを持ち込むことです。AMDにとって、CPUとdGPUで積極的に作業を実行しているアプリケーション・プログラミングを著しく簡素化できる、単一のユニファイドアドレス空間(CUDA6以降NVIDIAとのギャップを埋めている)に、CPUとdGPUを置くことができることを意味します。このドライバと共にHSAモデルを使用すると、クラスター内のノードを結合するために使用されるインフィニバンドのようなファブリックを持つ大規模クラスターのサポート/パフォーマンスを改善し、ディスパッチ・レイテンシを減少させるようなその他のニーズに、AMDは対応できることになります。新しいドライバの基本的な能力と組み合わせることで、AMDは競合と同等以上のクラスター機能セットを提供するいくつかの本当に必要な下地を本質において構築しています。
ヘテロジニアス・コンピュート・コンパイラー – OpenCLから分岐しC++に
ボルツマン・イニシアティブの第2の部分は、HPC向けのAMDの新しいコンパイラ、ヘテロジニアス・コンピュート・コンパイラです。同社のHSAコンパイラを完成した作業を基盤に、HCCは、HPCユーザが必要とするプログラミングに対応するためにAMDが行った二つの努力の内の最初の一つです。ユーザは概して、部分的に精彩を欠いたHPCソフトウェア環境をAMDのGPUに渡しています。
先に進む前の小さな背景として、NVIDIAとCUDAの最も初期の利点の一つは、OpenCLがCライク文法とOpenCLプログラミング用には明らかにローレベルの言語のみしかサポートできなかった時点で、CUDAは既にC++とその他のハイレベルプログラミング言語をサポートしていたと言うことがあります。AMDはその間オープンなエコシステムをサポートするために部分的にOpenCLを支援し続け、OpenCLが、ある意味で後の祭りであるが、今年、OpenCL 2.1の暫定リリースとOpenCL C ++カーネル言語で大きな進歩を遂げました。しかし、OpenCLはHPCスペースでの最小限の使用のみしか見ておらず、一部のベンダーしかOpenCL 2.xをサポートしていないと言うより複雑な事が起きています。その一部としてのAMDは、名前を氏名されるほどではありませんが、この時点では、OpenCL1.2までしかサポートできないNVIDIAが出遅れていることはよく知られていることです(しかし、何か新しいことをサポートするにはサビていないように見えます)。
HPCソフトウェアAPIニーズとしてOpenCLを当てにすることがもはやできないということを企業が明らかにした時、これらの開発の結果のようにAMDはソフトウェア戦略を変更しています。AMDは、OpenCLからとにかく逃げ腰になっているとは言いませんが、我々向けの説明会でAMDは引き続きOpenCLをサポートする意向があるということを明らかにした時でも、彼らの態度とプレゼンテーションを元にすると、このことは波風を立てることを避けるために中身の無い企業約束の常套手段のようにみえました。しかし、OpenCLがAMDがこれまで欲した物全てを提供したとしても、APIのサポートが断片化していることや、OpenCL C++の状況が今だに低いレベルにしか無いため、OpenCLを利用することは難しいということを実感します。このため、AMDは同時にかれら独自のAPIと環境を整えていくことになるでしょう。
この環境は、ヘテロジニアスコンピュート・コンパイラを中心に構築されます。ある意味CUDAに対するAMDの答えとしてのHCCは、CPUとGPU両方の単一のC/C ++/OpenMPコンパイラです。多くの最近のコンパイラプロジェクトのように、AMDはランタイム環境として機能するために以前説明したようにHSAの一部と同調するコンパイルを処理するためにClangとLLVMの一部を活用しています。
HCCの目的は、開発者が単一のソースファイル内に、単一の言語で、単一のコンパイラを使用してCPUとGPUのコードを書くことを可能にすることです。最終的には、開発者が行うC++プログラミング内の並列コールを簡単に行えるMicrosoft C++ AMPのようなものになります。おそらく、AMDとAMDのHPC利用者の予測として最も重要なことは、HCCは、GPUカーネル専用の別ソース・ファイルやOpenCL++まで利用し続けないといけない制限が必要とされないことです。
 HCCソースコード例
HCCソースコード例
全体的に、HCCは、2つの方法で並列処理を公開します。一番目は、C++ラムダコードを中心に構築された機能で、並列で実行でき、そしてどのようにその他のプログラムと相互作用するかというコードセグメントをはっきりと設定するための、parallel_for_eachのような、開発者がコールできる並列化可能な関数を持つ、C++ AMP式の並列処理の明示的な構文です。さらにハイレベルにある二番目の方法は、C++ 17への装備を今後予定しているパラレルSTL(標準テンプレートライブラリ)を、活用することになります。パラレルSTLは、GPU/アクセラレーターの実行のための多くの並列化の標準機能を含んでます。そして開発者はもはや並列実行の確かな様子をコントロールし明示的に説明する必要がないため物事を簡素化できます。このため開発者は、修正/拡張のためのベースとしてSTL関数を使うことができるのです。
最終的にHCCは、AMD GPUのためのGPUプログラミングを改良することおよび、環境により必要な機能をもたらすことを意図しています。基本的な並列性と標準の並列関数の即時追加に伴い、HCCもGPUやその他のアクセラレータのパフォーマンスを向上させるためにいくつかの機能を搭載します。これには、プリフェッチデータ、非同期演算カーネル、さらにはスクラッチパッドメモリ(すなわち、AMD LDS ローカルデータシェア)のサポートが含まれています。これらの機能でAMDは、HPCユーザーが欲しているプログラミング環境の一種、新たなHPCプログラマーにより歓迎される環境、そして同様にCUDAプログラマーにも歓迎される環境を提供できることを期待しています。
ポータビリティーのためのヘテロジニアス・コンピュート・インターフェース (HIP) – AMD GPUでCUDAをコンパイル
最後に、ボルツマンイニシアティブは、完全にCUDA開発者の世界に橋渡しをするAMDの取り組みです。CUDA開発者が望むことと同等以上のAMDのプログラミング環境を提供するためにHCCで、NVIDIAと同レベルでは必ずしも十分でないこと、CUDAの構文に慣れている開発者は何も変更したくないこと、そしてCUDAは何時でもどこでもすぐに利用されるわけではないことにAMDは気付きました。その問題の解決策は、CUDA開発者にAMD GPUに移植するための必要なツールを簡単にもたらす、ポータビリティのためのヘテロジニアス・コンピュート・インターフェース(HIP)です。

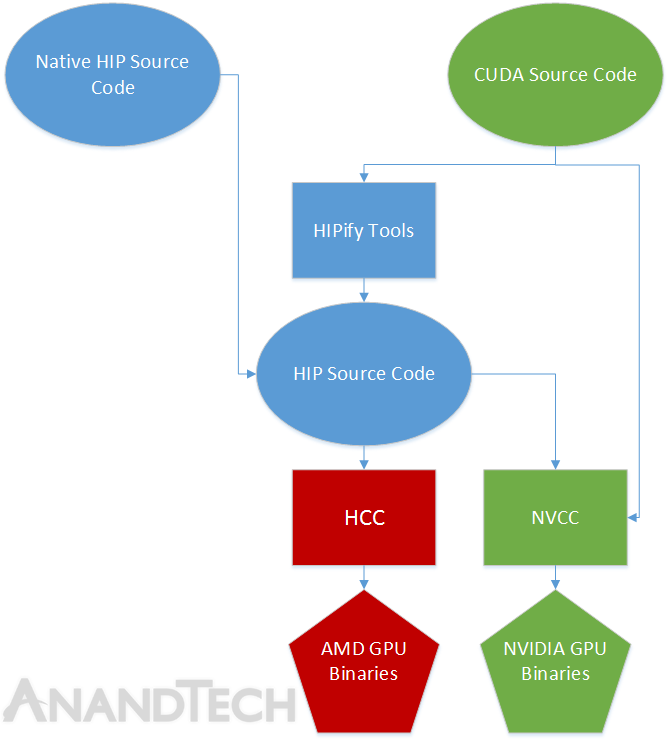
HIPを通して、AMDは、開発者がCUDAのような方法でAMD GPUをプログラムすることを可能にするCUDAのような構文(様々なHIP APIコマンド)を開発者に提供することで、HCCとCUDA間のギャプを埋めようとしています。一方で、HIPは、自動的にCUDAコードからHIPコードに変換することで、ポーティングをより簡素化するツールセット(HIPifyツール)も含んでいます。そしてついに、ネイティブで書かれようが変換されようが、一度コードがHIPになれば、NVCC(HIPサポートを追加するためにはHIPヘッダーファイルが必要ですが)でまたはHCC各々で、NVIDIAまたはAMDのいずれかのGPU用にコンパイルすることができます。
ここで明確にしないといけないことは、HIPは、AMDのGPU上でコンパイルされたCUDAプログラムを実行するための手段では無いということです。CUDAはNVIDIAの技術以外の何者でもありません。しかし、HIPはソース・ツー・ソース変換の手段で、そのため開発者はAMD GPUをターゲットにする場合でもはるかに簡単に時間をかけずに変換できます。開発者が通常自前で全てのコードを書き、そして特定のアーキテクチャー上で動作するように調整するHPCマーケットを考慮すると、ソース・ツー・ソース変換は、AMDがまさに必要とする物の大部分をカバーし、そしてAMDのGPU用コードをより良く最適化することができるハイレベル言語をCUDAコードにコンパイルするための機能をAMDが持っていることを意味します。
現在、AMDがCUDA機能の追加と最新のHIPを維持するかどうかを含むいくつかの不明点がありますが、より重要なことは、NVIDIAの反応がどうなのかと言う問題です。CUDAはあらゆる点でNVIDIAの物であり、特にOracle vs GoogleのJava APIのケースのような観点から見て、NVIDIAの許可なくCUDA APIを実装した時に、AMDを告訴しようとするかどうかです。AMDの法務部門は広範囲に問題を調査し、そしてGPUCCでLLVMにCUDAサポートを持ち込もうとしたGoogle自信の取り組みをとり、彼らは訴訟リスクは無いと信じています。個人的には、AMDの取り組みは、直接の競合に少しばかり挑発的なものを与えていると思いますが。最終的には、訴訟が起きた場合には、AMDとNVIDIAのみが処理することですが、指摘される必要がある何かでもあるわけです。
CUDAがマーケットを牽引して以来HPC企業の努力の妨げとなった、CUDAを実行できないと言う事実である最も大きな問題を、HIPを作成することで、AMDは解決しています。誰もが標準C++でプログラムすることができ、実行できればAMDは確かに幸せになるかもしれませんが、独自APIに対して互換性レイヤーは完璧な解決策になることはありません。しかし、CUDAで成長し、この時点でそれに定着したかなりのユーザーベースがあります。そして、かれらがNVIDIAからHPCマーケットシェアを奪い取ることを願っているならば、単純にCUDA互換性を持っている必要があります。

まとめると、ボルツマンイニシアティブでAMDは、HPCスペースで彼ら自身を再定義するための重要で非常に多くの必要なステップを踏んでいます。LinuxのヘッドレスOSサポートやユニファイドメモリ空間のために改良したドライバーレイヤ、直接のコンパイラー、C++単一ソースのコンパイル実行、そして確立されたCUDAユーザに届くためにCUDA互換レイヤを提供することで、AMDはついに問題のHPCサイドでかなり積極的になっており、そして彼らは、長い間これを作成するに必要だったことを多く議論した上で移動しています。この時点では、AMDはプロセスにおける品質ツールを提供するためにロードマップを提供する必要があります。それでもNVIDIAは良い製品を通じてHPCスペースでその場所を獲得していますし、簡単には排除できないでしょう。CUDAは開発者がそれを必要とした時を確実に掴んでいます。しかし、AMDにとって、彼らがボルツマンを実行することができるならば、5年目にして初めて、利益の上がるそして高収益性のHPCマーケットに対して成功するチャンスを持つことになるでしょう。
【株式会社エーキューブ について】
米国AMD Inc.との協業により、FirePro™シリーズの販売及びマーケティング・サポート、技術サポートなどの事業活動を行っております。
〒102-0076 東京都千代田区五番町二番地カサ・ド・タク30C www.acube-corp.com
【Sapphire PGSについて】
SAPPHIRE PGS (プロフェッショナルグラフィクスソリューション) は、プロフェッショナル・グラフィクスに関する SAPPHIRE Technology のビジネスユニットです。ワークステーションおよびプロフェッショナルクライアント向けに各種プロ用グラフィックディスプレイソリューションを提供しています。SAPPHIRE PGS は、あらゆる種類の3Dプロフェッショナル・アプリケーションをプロユーザー向けにサポートしています。産業分野のお客様に対して、SAPPHIRE PGS は、放送、デジタルサイネージ、医療、監視、ATC (航空交通管制)、およびその他の市場向けにディスプレイ関連のグラフィクスアプリケーションソリューションを統合しています。SAPPHIRE PGS は、お客様に最適なソリューション、および他社にはない販売前コンサルティングと販売後サービスの提供を大切にしています。
詳細情報については www.SapphirePGS.com をご参照ください。
【AMDについて】
AMD(NYSE:AMD)は、コンピュータ業界、グラフィックス、家電業界向けに革新的なマイクロプロセッサ・ソリューションを提供するグローバル・プロバイダです。AMDは、世界中のコンシューマおよびビジネス分野のお客様を支援する、徹底したお客様中心主義の理念に基づくソリューションを提供します。それにより、オープンな技術革新の促進、選択肢の拡大、さらに業界の発展に向けて努力します。日本AMD株式会社は、AMDの日本法人です。詳細については、www.amd.com(英語)または http://www.amd.co.jp(日本語)をご覧ください。
<本件リリースに関するお問い合わせ先>
株式会社エーキューブ マーケティング担当: 鈴木雄一
e-mail: このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。
AMDは、Advanced Micro Devices, Inc.の商標です。AUBEは、株式会社エーキューブの商標です。その他すべての名称は、情報提供の目的においてのみ記載されているもので、名称を所有する企業・団体などの商標である場合があります。
サーバーカード、FirePro SシリーズのHPC能力に焦点あてたるためのショーに専念するAMDから、SC15における重要な第2番目のアナウンスが発表されました。
我々が過去2週間傍聴した事前説明会のすべての中でも、本日のAMDの発表はこれまで最も重要なことです。そして、それは SCがAMDのホームグラウンド、テキサス州オースティンで開催された時にこれが発表されたことは当然のことといえます。
何がAMDを熱狂させたのでしょうか? 要約すると、同社はHPCソフトウェア計画の大規模な見直しに着手しようとしています。統計力学の父、ルードリッヒ・ボルツマンにちなんでボルツマン・イニシアティブと呼ばれています。NVIDIAとのギャップを埋めて競争(および互換性!)環境を提供するために、AMDは彼らのHPCソフトウェアエコシステムの再開発努力にもっと取り組むことになるでしょう。このことを念頭に置いて、先に進んでみましょう。
ヘッドレスLinuxとHSAベースGPUの環境
おそらく、ボルツマン・イニシアティブの土台は、AMDの他の計画をサポートするために見直しと改善されたAMDのドライバーと共にあります。同社は、特にLinuxのヘッドレス操作のために専用の64-bit Linuxドライバーをビルドすることになるでしょう。AMDは実際、Linuxのヘッドレス操作(そのヘッドレスOpenCLに先立った実行環境はすこしハッキング気味でしたが)と完成した新しいドライバに昨年からフォーカスしてきました。
しかしそのことよりも重要なのは、ヘッドレスLinuxドライバは、HSA拡張環境を実装するだろうことです。それは、AMDのFireProディスクリートGPUにヘテロジニアス・システム・アーキテクチャ(HSA)の多くの利点をもたらすでしょう。AMDがHSA+と呼んでいるこの環境は、特にディスクリートGPUでHSAをサポートするための拡張機能を追加することで、正式なHSA規格を作り直します。拡張機能自体は標準規格にはならない予定ですが、HSAファウンデーションは、APU風の真のインテグレートデバイスに焦点をあてているので、それらの拡張機能はすぐに主流のHSAとして上流で受け入れられそうにはありません。このため、AMDは将来この拡張機能をオープンソースとしてリリースするでしょう。
ディスクリートGPU(dGPU)にHSAを拡張する目的は、以前の約束を満たす以外にも、dGPUに実用的なHSA実行モデルの利点を出来る限り多くを持ち込むことです。AMDにとって、CPUとdGPUで積極的に作業を実行しているアプリケーション・プログラミングを著しく簡素化できる、単一のユニファイドアドレス空間(CUDA6以降NVIDIAとのギャップを埋めている)に、CPUとdGPUを置くことができることを意味します。このドライバと共にHSAモデルを使用すると、クラスター内のノードを結合するために使用されるインフィニバンドのようなファブリックを持つ大規模クラスターのサポート/パフォーマンスを改善し、ディスパッチ・レイテンシを減少させるようなその他のニーズに、AMDは対応できることになります。新しいドライバの基本的な能力と組み合わせることで、AMDは競合と同等以上のクラスター機能セットを提供するいくつかの本当に必要な下地を本質において構築しています。
ヘテロジニアス・コンピュート・コンパイラー – OpenCLから分岐しC++に
ボルツマン・イニシアティブの第2の部分は、HPC向けのAMDの新しいコンパイラ、ヘテロジニアス・コンピュート・コンパイラです。同社のHSAコンパイラを完成した作業を基盤に、HCCは、HPCユーザが必要とするプログラミングに対応するためにAMDが行った二つの努力の内の最初の一つです。ユーザは概して、部分的に精彩を欠いたHPCソフトウェア環境をAMDのGPUに渡しています。
先に進む前の小さな背景として、NVIDIAとCUDAの最も初期の利点の一つは、OpenCLがCライク文法とOpenCLプログラミング用には明らかにローレベルの言語のみしかサポートできなかった時点で、CUDAは既にC++とその他のハイレベルプログラミング言語をサポートしていたと言うことがあります。AMDはその間オープンなエコシステムをサポートするために部分的にOpenCLを支援し続け、OpenCLが、ある意味で後の祭りであるが、今年、OpenCL 2.1の暫定リリースとOpenCL C ++カーネル言語で大きな進歩を遂げました。しかし、OpenCLはHPCスペースでの最小限の使用のみしか見ておらず、一部のベンダーしかOpenCL 2.xをサポートしていないと言うより複雑な事が起きています。その一部としてのAMDは、名前を氏名されるほどではありませんが、この時点では、OpenCL1.2までしかサポートできないNVIDIAが出遅れていることはよく知られていることです(しかし、何か新しいことをサポートするにはサビていないように見えます)。
HPCソフトウェアAPIニーズとしてOpenCLを当てにすることがもはやできないということを企業が明らかにした時、これらの開発の結果のようにAMDはソフトウェア戦略を変更しています。AMDは、OpenCLからとにかく逃げ腰になっているとは言いませんが、我々向けの説明会でAMDは引き続きOpenCLをサポートする意向があるということを明らかにした時でも、彼らの態度とプレゼンテーションを元にすると、このことは波風を立てることを避けるために中身の無い企業約束の常套手段のようにみえました。しかし、OpenCLがAMDがこれまで欲した物全てを提供したとしても、APIのサポートが断片化していることや、OpenCL C++の状況が今だに低いレベルにしか無いため、OpenCLを利用することは難しいということを実感します。このため、AMDは同時にかれら独自のAPIと環境を整えていくことになるでしょう。
この環境は、ヘテロジニアスコンピュート・コンパイラを中心に構築されます。ある意味CUDAに対するAMDの答えとしてのHCCは、CPUとGPU両方の単一のC/C ++/OpenMPコンパイラです。多くの最近のコンパイラプロジェクトのように、AMDはランタイム環境として機能するために以前説明したようにHSAの一部と同調するコンパイルを処理するためにClangとLLVMの一部を活用しています。
HCCの目的は、開発者が単一のソースファイル内に、単一の言語で、単一のコンパイラを使用してCPUとGPUのコードを書くことを可能にすることです。最終的には、開発者が行うC++プログラミング内の並列コールを簡単に行えるMicrosoft C++ AMPのようなものになります。おそらく、AMDとAMDのHPC利用者の予測として最も重要なことは、HCCは、GPUカーネル専用の別ソース・ファイルやOpenCL++まで利用し続けないといけない制限が必要とされないことです。
HCCソースコード例全体的に、HCCは、2つの方法で並列処理を公開します。一番目は、C++ラムダコードを中心に構築された機能で、並列で実行でき、そしてどのようにその他のプログラムと相互作用するかというコードセグメントをはっきりと設定するための、parallel_for_eachのような、開発者がコールできる並列化可能な関数を持つ、C++ AMP式の並列処理の明示的な構文です。さらにハイレベルにある二番目の方法は、C++ 17への装備を今後予定しているパラレルSTL(標準テンプレートライブラリ)を、活用することになります。パラレルSTLは、GPU/アクセラレーターの実行のための多くの並列化の標準機能を含んでます。そして開発者はもはや並列実行の確かな様子をコントロールし明示的に説明する必要がないため物事を簡素化できます。このため開発者は、修正/拡張のためのベースとしてSTL関数を使うことができるのです。
最終的にHCCは、AMD GPUのためのGPUプログラミングを改良することおよび、環境により必要な機能をもたらすことを意図しています。基本的な並列性と標準の並列関数の即時追加に伴い、HCCもGPUやその他のアクセラレータのパフォーマンスを向上させるためにいくつかの機能を搭載します。これには、プリフェッチデータ、非同期演算カーネル、さらにはスクラッチパッドメモリ(すなわち、AMD LDS ローカルデータシェア)のサポートが含まれています。これらの機能でAMDは、HPCユーザーが欲しているプログラミング環境の一種、新たなHPCプログラマーにより歓迎される環境、そして同様にCUDAプログラマーにも歓迎される環境を提供できることを期待しています。
ポータビリティーのためのヘテロジニアス・コンピュート・インターフェース (HIP) – AMD GPUでCUDAをコンパイル
最後に、ボルツマンイニシアティブは、完全にCUDA開発者の世界に橋渡しをするAMDの取り組みです。CUDA開発者が望むことと同等以上のAMDのプログラミング環境を提供するためにHCCで、NVIDIAと同レベルでは必ずしも十分でないこと、CUDAの構文に慣れている開発者は何も変更したくないこと、そしてCUDAは何時でもどこでもすぐに利用されるわけではないことにAMDは気付きました。その問題の解決策は、CUDA開発者にAMD GPUに移植するための必要なツールを簡単にもたらす、ポータビリティのためのヘテロジニアス・コンピュート・インターフェース(HIP)です。
HIPを通して、AMDは、開発者がCUDAのような方法でAMD GPUをプログラムすることを可能にするCUDAのような構文(様々なHIP APIコマンド)を開発者に提供することで、HCCとCUDA間のギャプを埋めようとしています。一方で、HIPは、自動的にCUDAコードからHIPコードに変換することで、ポーティングをより簡素化するツールセット(HIPifyツール)も含んでいます。そしてついに、ネイティブで書かれようが変換されようが、一度コードがHIPになれば、NVCC(HIPサポートを追加するためにはHIPヘッダーファイルが必要ですが)でまたはHCC各々で、NVIDIAまたはAMDのいずれかのGPU用にコンパイルすることができます。
ここで明確にしないといけないことは、HIPは、AMDのGPU上でコンパイルされたCUDAプログラムを実行するための手段では無いということです。CUDAはNVIDIAの技術以外の何者でもありません。しかし、HIPはソース・ツー・ソース変換の手段で、そのため開発者はAMD GPUをターゲットにする場合でもはるかに簡単に時間をかけずに変換できます。開発者が通常自前で全てのコードを書き、そして特定のアーキテクチャー上で動作するように調整するHPCマーケットを考慮すると、ソース・ツー・ソース変換は、AMDがまさに必要とする物の大部分をカバーし、そしてAMDのGPU用コードをより良く最適化することができるハイレベル言語をCUDAコードにコンパイルするための機能をAMDが持っていることを意味します。
現在、AMDがCUDA機能の追加と最新のHIPを維持するかどうかを含むいくつかの不明点がありますが、より重要なことは、NVIDIAの反応がどうなのかと言う問題です。CUDAはあらゆる点でNVIDIAの物であり、特にOracle vs GoogleのJava APIのケースのような観点から見て、NVIDIAの許可なくCUDA APIを実装した時に、AMDを告訴しようとするかどうかです。AMDの法務部門は広範囲に問題を調査し、そしてGPUCCでLLVMにCUDAサポートを持ち込もうとしたGoogle自信の取り組みをとり、彼らは訴訟リスクは無いと信じています。個人的には、AMDの取り組みは、直接の競合に少しばかり挑発的なものを与えていると思いますが。最終的には、訴訟が起きた場合には、AMDとNVIDIAのみが処理することですが、指摘される必要がある何かでもあるわけです。
CUDAがマーケットを牽引して以来HPC企業の努力の妨げとなった、CUDAを実行できないと言う事実である最も大きな問題を、HIPを作成することで、AMDは解決しています。誰もが標準C++でプログラムすることができ、実行できればAMDは確かに幸せになるかもしれませんが、独自APIに対して互換性レイヤーは完璧な解決策になることはありません。しかし、CUDAで成長し、この時点でそれに定着したかなりのユーザーベースがあります。そして、かれらがNVIDIAからHPCマーケットシェアを奪い取ることを願っているならば、単純にCUDA互換性を持っている必要があります。
まとめると、ボルツマンイニシアティブでAMDは、HPCスペースで彼ら自身を再定義するための重要で非常に多くの必要なステップを踏んでいます。LinuxのヘッドレスOSサポートやユニファイドメモリ空間のために改良したドライバーレイヤ、直接のコンパイラー、C++単一ソースのコンパイル実行、そして確立されたCUDAユーザに届くためにCUDA互換レイヤを提供することで、AMDはついに問題のHPCサイドでかなり積極的になっており、そして彼らは、長い間これを作成するに必要だったことを多く議論した上で移動しています。この時点では、AMDはプロセスにおける品質ツールを提供するためにロードマップを提供する必要があります。それでもNVIDIAは良い製品を通じてHPCスペースでその場所を獲得していますし、簡単には排除できないでしょう。CUDAは開発者がそれを必要とした時を確実に掴んでいます。しかし、AMDにとって、彼らがボルツマンを実行することができるならば、5年目にして初めて、利益の上がるそして高収益性のHPCマーケットに対して成功するチャンスを持つことになるでしょう。
【株式会社エーキューブ について】
米国AMD Inc.との協業により、FirePro™シリーズの販売及びマーケティング・サポート、技術サポートなどの事業活動を行っております。
〒102-0076 東京都千代田区五番町二番地カサ・ド・タク30C www.acube-corp.com
【Sapphire PGSについて】
SAPPHIRE PGS (プロフェッショナルグラフィクスソリューション) は、プロフェッショナル・グラフィクスに関する SAPPHIRE Technology のビジネスユニットです。ワークステーションおよびプロフェッショナルクライアント向けに各種プロ用グラフィックディスプレイソリューションを提供しています。SAPPHIRE PGS は、あらゆる種類の3Dプロフェッショナル・アプリケーションをプロユーザー向けにサポートしています。産業分野のお客様に対して、SAPPHIRE PGS は、放送、デジタルサイネージ、医療、監視、ATC (航空交通管制)、およびその他の市場向けにディスプレイ関連のグラフィクスアプリケーションソリューションを統合しています。SAPPHIRE PGS は、お客様に最適なソリューション、および他社にはない販売前コンサルティングと販売後サービスの提供を大切にしています。
詳細情報については www.SapphirePGS.com をご参照ください。
【AMDについて】
AMD(NYSE:AMD)は、コンピュータ業界、グラフィックス、家電業界向けに革新的なマイクロプロセッサ・ソリューションを提供するグローバル・プロバイダです。AMDは、世界中のコンシューマおよびビジネス分野のお客様を支援する、徹底したお客様中心主義の理念に基づくソリューションを提供します。それにより、オープンな技術革新の促進、選択肢の拡大、さらに業界の発展に向けて努力します。日本AMD株式会社は、AMDの日本法人です。詳細については、www.amd.com(英語)または http://www.amd.co.jp(日本語)をご覧ください。
<本件リリースに関するお問い合わせ先>
株式会社エーキューブ マーケティング担当: 鈴木雄一
e-mail: このメールアドレスはスパムボットから保護されています。閲覧するにはJavaScriptを有効にする必要があります。
AMDは、Advanced Micro Devices, Inc.の商標です。AUBEは、株式会社エーキューブの商標です。その他すべての名称は、情報提供の目的においてのみ記載されているもので、名称を所有する企業・団体などの商標である場合があります。
ACUBE、最新GPUチップ搭載 4画面出力、LowProfile対応グラフィックスボード 「AMD FirePro™ W4300 」をリリース
【概要】
株式会社エーキューブ(本社:東京都千代田区、代表取締役:武藤和彦)は、3Dグラフィック アクセラレータ AMD FirePro™ 3D Graphicsシリーズより、ロープロファイル対応、PCI Express 3.0×16バス対応、Mini DisplayPortを搭載したアクセラレータ「AMD FirePro™ W4300」を発表いたしました。
株式会社エーキューブ(本社:東京都千代田区、代表取締役:武藤和彦)は、3Dグラフィック アクセラレータ AMD FirePro™ 3D Graphicsシリーズより、ロープロファイル対応、PCI Express 3.0×16バス対応、Mini DisplayPortを搭載したアクセラレータ「AMD FirePro™ W4300」を発表いたしました。
年末年始休暇のお知らせ
いつも弊社製品をご利用いただきありがとうございます。
2015年12月30日(水)~ 2016年1月4日(月)まで、
年末年始のため、休業とさせていただきます。
サポート業務も2015年12月30日(水)~ 2016年1月4日(月)まで休業となります。
ご迷惑をおかけいたしますが、何卒ご理解賜りますようお願い申し上げます。
(2016年1月5日(火)より通常通りの対応となります。)
サポートに関しては、メールおよびFAXでのお問い合わせは上記期間中も承っております。
弊社からの回答は、2016年1月5日(火)より順次行わせていただきますので、ご回答をお送りするまでに時間がかかることがございますが、予めご了承ください。
・お問い合わせ窓口
ACUBEサポートセンター
TEL : 03-3261-4311(土日祝日を除く 10:00~13:00/ 14:00~16:00)
FAX : 03-3221-5953
2015年12月30日(水)~ 2016年1月4日(月)まで、
年末年始のため、休業とさせていただきます。
サポート業務も2015年12月30日(水)~ 2016年1月4日(月)まで休業となります。
ご迷惑をおかけいたしますが、何卒ご理解賜りますようお願い申し上げます。
(2016年1月5日(火)より通常通りの対応となります。)
サポートに関しては、メールおよびFAXでのお問い合わせは上記期間中も承っております。
弊社からの回答は、2016年1月5日(火)より順次行わせていただきますので、ご回答をお送りするまでに時間がかかることがございますが、予めご了承ください。
・お問い合わせ窓口
ACUBEサポートセンター
TEL : 03-3261-4311(土日祝日を除く 10:00~13:00/ 14:00~16:00)
FAX : 03-3221-5953
超高解像度4K(3840x 2160p @ 60Hz)に対応、DisplayPort/Mini DisplayPort to HDMI2.0変換アダプタを発表
株式会社エーキューブ(本社:東京都千代田区、代表取締役:武藤和彦)は、超高解像度出力に対応した、DisplayPortおよびMini DisplayPortからHDMI2.0へ変換するアダプタの発売を開始いたします。
ACUBEは、DisplayPort/Mini DisplayPortを搭載したCAD(コンピュータ支援設計)、DCC(デジタル・コンテンツ制作)、医療用画像処理用途等、プロフェッショナル向け最新グラフィックスボード「AMD FireProグラフィックスボード」シリーズの取扱い・販売をしており、今回の変換アダプタは、これらの製品に対応したものです。また、本ケーブルを複数使用することによって、4Kのマルチディスプレイ構成にも対応いたしました。
DisplayPort/Mini DisplayPortは次世代デジタルモニタインターフェースとして2006年にVESAによって発表され、現在発売されているモニタにはDisplayPortの搭載が標準化されつつあるが、実際に使用されているモニタはHDMIやDVIでの接続がまだまだ多いという現状にあります。
今回発表の変換アダプタは、現在ご使用中のモニタでも最新テクノロジ及びハイパフォーマンスのAMD FireProグラフィックスボードをご利用頂くための最適なソリューションとしてご提供致します。
ACUBEは、DisplayPort/Mini DisplayPortを搭載したCAD(コンピュータ支援設計)、DCC(デジタル・コンテンツ制作)、医療用画像処理用途等、プロフェッショナル向け最新グラフィックスボード「AMD FireProグラフィックスボード」シリーズの取扱い・販売をしており、今回の変換アダプタは、これらの製品に対応したものです。また、本ケーブルを複数使用することによって、4Kのマルチディスプレイ構成にも対応いたしました。
DisplayPort/Mini DisplayPortは次世代デジタルモニタインターフェースとして2006年にVESAによって発表され、現在発売されているモニタにはDisplayPortの搭載が標準化されつつあるが、実際に使用されているモニタはHDMIやDVIでの接続がまだまだ多いという現状にあります。
今回発表の変換アダプタは、現在ご使用中のモニタでも最新テクノロジ及びハイパフォーマンスのAMD FireProグラフィックスボードをご利用頂くための最適なソリューションとしてご提供致します。